CVPR 2026
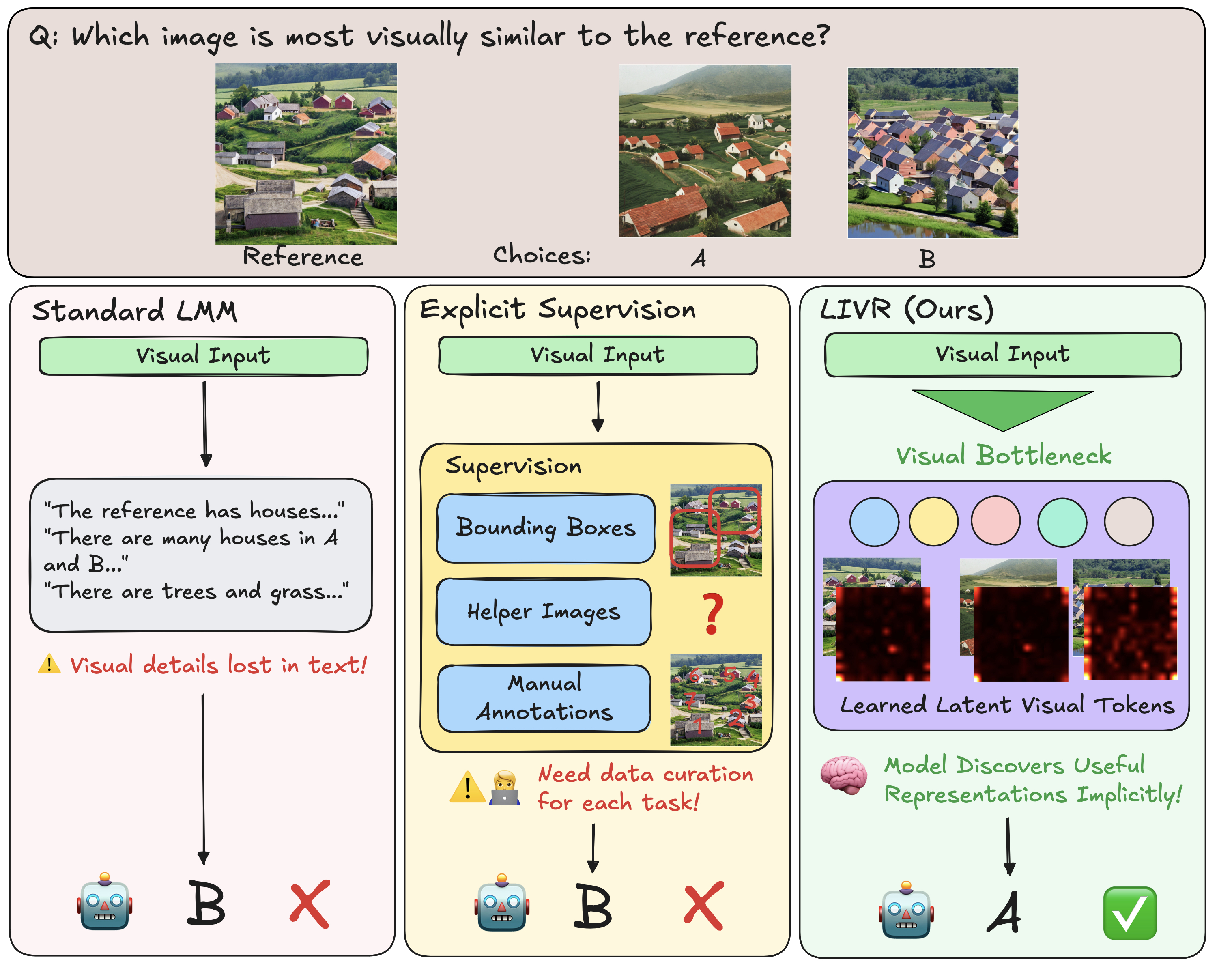
We show that LMMs can discover the visual representations they need by themselves, learning task-adaptive latent visual tokens without helper images, boxes, crops, depth maps, or chain-of-thought annotations.
While Large Multimodal Models (LMMs) have made significant progress, they remain largely text-centric, relying on language as their core reasoning modality. As a result, they are limited in their ability to handle reasoning tasks that are predominantly visual. Recent approaches have sought to address this by supervising intermediate visual steps with helper images, depth maps, or image crops. However, these strategies impose restrictive priors on what "useful" visual abstractions look like, add heavy annotation costs, and struggle to generalize across tasks. To address this critical limitation, we propose Latent Implicit Visual Reasoning (LIVR), a task-agnostic mechanism that trains LMMs to discover and use latent visual reasoning tokens without explicit intermediate supervision. These tokens attend globally and re-encode the image in a task-adaptive way, enabling the model to extract relevant visual information without hand-crafted supervision. LIVR consistently outperforms direct supervised fine-tuning across diverse vision-centric tasks and multiple LMM backbones. In broader comparisons, LIVR remains competitive with or outperforms prior text-based and explicit-visual-intermediate reasoning methods, while requiring no additional intermediate supervision such as helper images, bounding boxes, image crops, depth maps, or chain-of-thought annotations.
Recent methods try to close this gap by supervising intermediate visual steps with helper images, depth maps, image crops, bounding boxes, or similar artifacts. These intermediates can guide a model, but they also decide in advance what a useful visual abstraction should look like, adding curation costs and task-specific priors that can make generalization harder.
LIVR takes a different route by training LMMs to discover latent visual reasoning tokens directly from final-answer supervision. These tokens attend globally and re-encode the image in a task-adaptive way, giving the model an internal visual workspace for extracting relevant evidence. Across diverse vision-centric tasks and multiple LMM backbones, LIVR consistently improves over direct supervised fine-tuning and remains competitive with or better than prior text-based and explicit-visual-intermediate reasoning methods, while requiring no helper images, boxes, crops, depth maps, or chain-of-thought annotations.
LIVR augments a vision-language model with a small set of learnable latent visual reasoning tokens appended to the prompt. Instead of asking the model to verbalize or render intermediate steps, these tokens are inserted into the input sequence and used as an internal visual workspace.
Training has two stages. In Stage 1, LIVR changes the attention mask to create a visual bottleneck: answer tokens cannot attend directly to image tokens, and prompt tokens are also prevented from leaking image information forward. The answer can use the image only through the latent tokens, forcing them to attend globally and re-encode task-relevant visual evidence.
In Stage 2, the standard attention mask is restored. The model can then combine the original image tokens with the latent tokens that were trained to carry useful visual abstractions. The loss is still computed only on answer tokens, so the method does not require boxes, crops, helper images, depth maps, masks, text rationales, or other intermediate supervision.
At inference time, the latents are inserted once with the prompt and the model decodes the answer normally. Since they are not autoregressive output tokens, LIVR unlocks the power of expressive latents without the associated inference overhead.
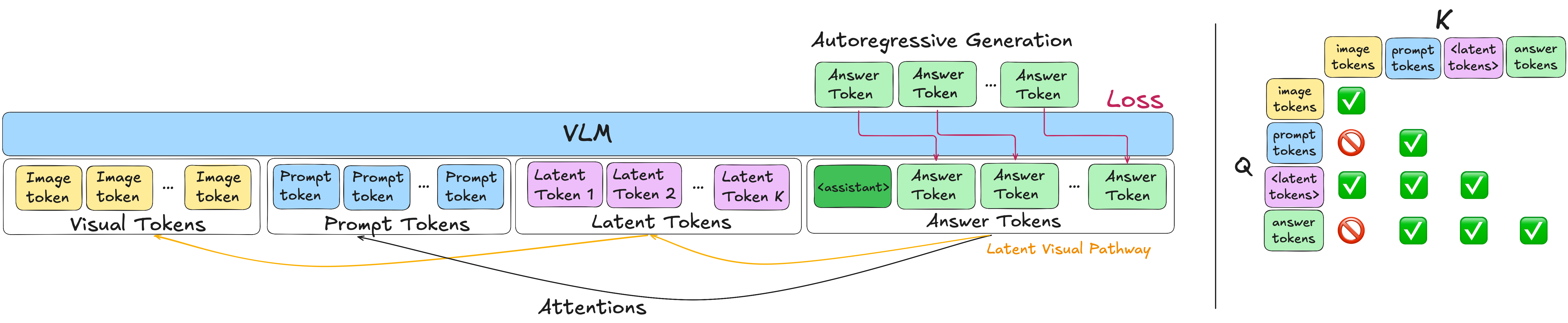
LIVR trains latent tokens through bottleneck attention masking. During bottleneck training, the answer must route visual evidence through the latent tokens; after the mask is restored, the model uses both the original image tokens and the learned latent workspace.
First, we compare LIVR to direct supervised fine-tuning (SFT) in a data-matched setting. Then, we compare our method with existing methods that are trained with textual chain-of-thought or explicit visual intermediates. Scores follow the paper convention: bold marks the best method in a block, and underlining marks the second-best score.
| Method | Counting | Jigsaw | Local. | Vis. Corr. | Art Style | Sem. Corr. | Func. Corr. | Rel. Refl. | Vis. Sim. | Mean |
|---|---|---|---|---|---|---|---|---|---|---|
| Random Choice | 11.11 | 50.00 | 50.00 | 25.00 | 50.00 | 25.00 | 25.00 | 33.33 | 50.00 | 35.49 |
| Qwen2.5-VL-3B-Instruct | ||||||||||
| Zero-shot | 46.78 | 49.33 | 56.56 | 29.86 | 55.56 | 32.37 | 26.71 | 45.52 | 50.37 | 43.67 |
| Direct SFT | 60.04 | 53.33 | 75.41 | 88.00 | 83.76 | 41.01 | 18.49 | 44.78 | 89.63 | 61.61 |
| LIVR | 63.64 | 65.33 | 79.51 | 90.43 | 87.18 | 46.76 | 31.51 | 51.49 | 94.82 | 67.85 |
| Delta vs SFT | +3.60 | +12.00 | +4.10 | +2.43 | +3.42 | +5.75 | +13.02 | +6.71 | +5.19 | +6.24 |
| Qwen3-VL-4B-Instruct | ||||||||||
| Zero-shot | 58.52 | 84.67 | 59.02 | 55.43 | 77.78 | 39.57 | 31.51 | 47.76 | 82.22 | 59.61 |
| Direct SFT | 66.86 | 83.33 | 79.51 | 90.86 | 78.63 | 61.15 | 58.90 | 56.72 | 91.11 | 74.12 |
| LIVR | 66.67 | 85.33 | 83.61 | 93.29 | 81.20 | 64.75 | 67.81 | 62.69 | 92.59 | 77.55 |
| Delta vs SFT | -0.19 | +2.00 | +4.10 | +2.43 | +2.57 | +3.60 | +8.91 | +5.97 | +1.48 | +3.43 |
| LLaVA-OneVision-1.5-4B-Instruct | ||||||||||
| Zero-shot | 53.98 | 56.00 | 56.56 | 36.86 | 56.41 | 29.50 | 21.92 | 35.82 | 51.11 | 44.24 |
| Direct SFT | 60.42 | 65.33 | 68.85 | 86.86 | 76.92 | 46.76 | 23.29 | 52.24 | 92.59 | 63.70 |
| LIVR | 63.64 | 70.67 | 72.95 | 88.71 | 80.34 | 51.08 | 50.69 | 53.73 | 91.85 | 69.30 |
| Delta vs SFT | +3.22 | +5.34 | +4.10 | +1.85 | +3.42 | +4.32 | +27.40 | +1.49 | -0.74 | +5.60 |
Mean accuracy is averaged over counting, jigsaw, localization, visual correspondence, art style classification, semantic correspondence, functional correspondence, relative reflectance, and visual similarity.
| Method | Counting | Local. | Vis. Corr. | Sem. Corr. | Func. Corr. | Rel. Refl. | Mean |
|---|---|---|---|---|---|---|---|
| Zero-shot | 58.52 | 59.02 | 55.43 | 39.57 | 31.51 | 47.76 | 48.64 |
| Direct SFT | 66.10 | 77.87 | 91.29 | 62.59 | 63.01 | 56.72 | 69.60 |
| LIVR | 67.80 | 81.97 | 92.00 | 67.63 | 64.38 | 60.45 | 72.37 |
| Delta vs SFT | +1.70 | +4.10 | +0.71 | +5.04 | +1.37 | +3.73 | +2.77 |
Multi-task fine-tuning uses Qwen3-VL-4B-Instruct and a six-task mixture. LIVR improves on every task while using the same direct question-answer supervision as Direct SFT.
These tables compare LIVR with recent methods that use external intermediate supervision, generated visual steps, or RL-style training.
| Method | SAT Val | BLINK-3 | RoboSpatial |
|---|---|---|---|
| Qwen2.5VL-3B | 46.1 | 44.4 | 54.4 |
| + SFT direct | 58.3 | 46.4 | 62.3 |
| + Vanilla GRPO | 50.0 | 46.5 | 69.7 |
| Text-CoT (SFT+GRPO) | 58.7 | 45.4 | -- |
| ViGoRL-3B | 62.9 | 48.5 | 67.1 |
| LIVR-3B | 85.6 | 59.5 | 66.7 |
All rows except LIVR-3B are reported from ViGoRL.
| Method | MMVP | V* | BLINK-5 |
|---|---|---|---|
| Qwen2.5-VL-7B | 66.7 | 78.5 | 53.66 |
| PAPO | 54.3 | 36.1 | 54.81 |
| Vision-R1 | 46.7 | 70.2 | 42.76 |
| PixelReasoner | 67.0 | 80.1 | 54.52 |
| LVR-7B | 71.7 | 80.6 | 55.37 |
| LIVR-7B | 75.3 | 80.1 | 54.28 |
All rows except LIVR-7B are reported from LVR.
The learned tokens are not merely extra capacity. When visualized through latent-to-image attention, they focus on regions needed to resolve the task: semantic correspondences, localized objects, and counted instances. This suggests the bottleneck stage trains latents to encode task-relevant visual evidence without prescribing what the intermediate representation should be.

Latent-to-image attention maps across semantic correspondence, localization, and counting. The dominant attention patterns align with the regions or objects needed to answer each question.
Latent visual reasoning does not need to be hand-designed. By changing the training dynamics, we can let VLMs discover internal visual abstractions for solving multimodal tasks.
The result is a task-agnostic mechanism for perception-heavy problems where the right intermediate representation is ambiguous: comparing style, tracking correspondence, solving jigsaw layouts, judging reflectance, or recognizing similarity patterns that are awkward to express in text.
Code and data are coming soon!
@inproceedings{li2026latent,
title = {Latent Implicit Visual Reasoning},
author = {Li, Kelvin and Shang, Chuyi and Karlinsky, Leonid and Feris, Rogerio and Darrell, Trevor and Herzig, Roei},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026}
}