publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- CVPR 2026
 Latent Implicit Visual ReasoningCVPR, 2026
Latent Implicit Visual ReasoningCVPR, 2026While Large Multimodal Models (LMMs) have made significant progress, they remain largely text-centric, relying on language as their core reasoning modality. As a result, they are limited in their ability to handle reasoning tasks that are predominantly visual. Recent approaches have sought to address this by supervising intermediate visual steps with helper images, depth maps, or image crops. However, these strategies impose restrictive priors on what “useful” visual abstractions look like, add heavy annotation costs, and struggle to generalize across tasks. To address this critical limitation, we propose a task-agnostic mechanism that trains LMMs to discover and use visual reasoning tokens without explicit supervision. These tokens attend globally and re-encode the image in a task-adaptive way, enabling the model to extract relevant visual information without hand-crafted supervision. Our approach outperforms direct fine-tuning and achieves state-of-the-art results on a diverse range of vision-centric tasks – including those where intermediate abstractions are hard to specify – while also generalizing to multi-task instruction tuning.
2024
- EMNLP 2024
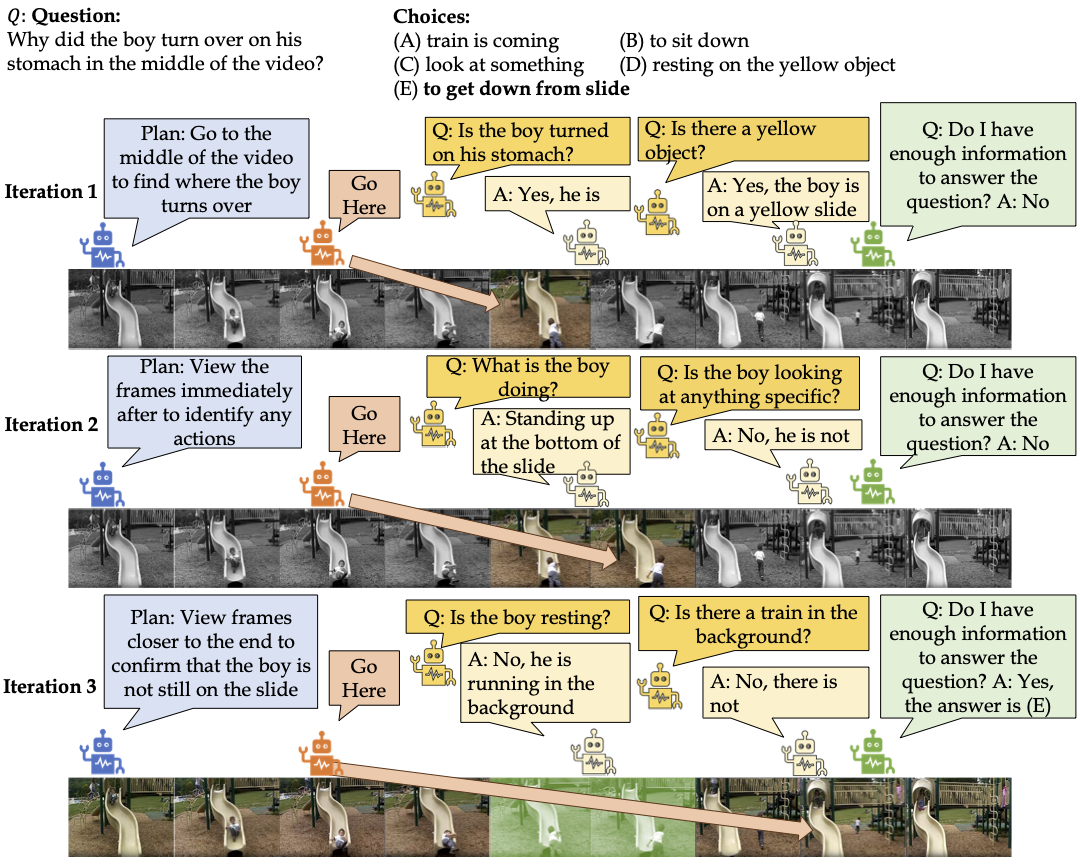 TraveLER: A Modular Multi-LMM Agent Framework for Video Question-AnsweringEMNLP, 2024
TraveLER: A Modular Multi-LMM Agent Framework for Video Question-AnsweringEMNLP, 2024Recently, image-based Large Multimodal Models (LMMs) have made significant progress in video question-answering (VideoQA) using a frame-wise approach by leveraging large-scale pretraining in a zero-shot manner. Nevertheless, these models need to be capable of finding relevant information, extracting it, and answering the question simultaneously. Currently, existing methods perform all of these steps in a single pass without being able to adapt if insufficient or incorrect information is collected. To overcome this, we introduce a modular multi-LMM agent framework based on several agents with different roles, instructed by a Planner agent that updates its instructions using shared feedback from the other agents. Specifically, we propose TraveLER, a method that can create a plan to "Traverse" through the video, ask questions about individual frames to "Locate" and store key information, and then "Evaluate" if there is enough information to answer the question. Finally, if there is not enough information, our method is able to "Replan" based on its collected knowledge. Through extensive experiments, we find that the proposed TraveLER approach improves performance on several VideoQA benchmarks without the need to fine-tune on specific datasets. Our code is available at https://github.com/traveler-framework/TraveLER
2023
- CVEU @ ICCV 2023
 LUSE: Using LLMs for Unsupervised Step Extraction in Instructional VideosICCV CVEU Workshop, 2023
LUSE: Using LLMs for Unsupervised Step Extraction in Instructional VideosICCV CVEU Workshop, 2023In this work, we introduce an unsupervised languageonly approach to automatically segment and identify steps in instructional videos. Parsing a video into its steps has several use cases-training video action recognition models to recognize steps, creating visual summaries highlighting relevant steps, identifying mistakes in steps of the video, and retrieving/localizing steps in the video to name a few. Our framework LUSE, zero-shot prompts a Large Language Model (LLM) to extract steps from the transcript of a single instructional video. Next, the steps across several videos of the same task are consolidated to generate a general set of steps for the task, via a second pass through the LLM, and are then localized back in the transcript of each video. Existing datasets for steps rely on manual annotations which are expensive to collect and oftentimes subjective. Our fully automated approach overcomes these issues and generates competitive quality step labels, as highlighted by our qualitative examples. Furthermore, we fine-tune a state-of-theart image captioning model on our generated steps to show that the resulting output has better qualitative step descriptions and denser coverage compared to existing manually annotated datasets.